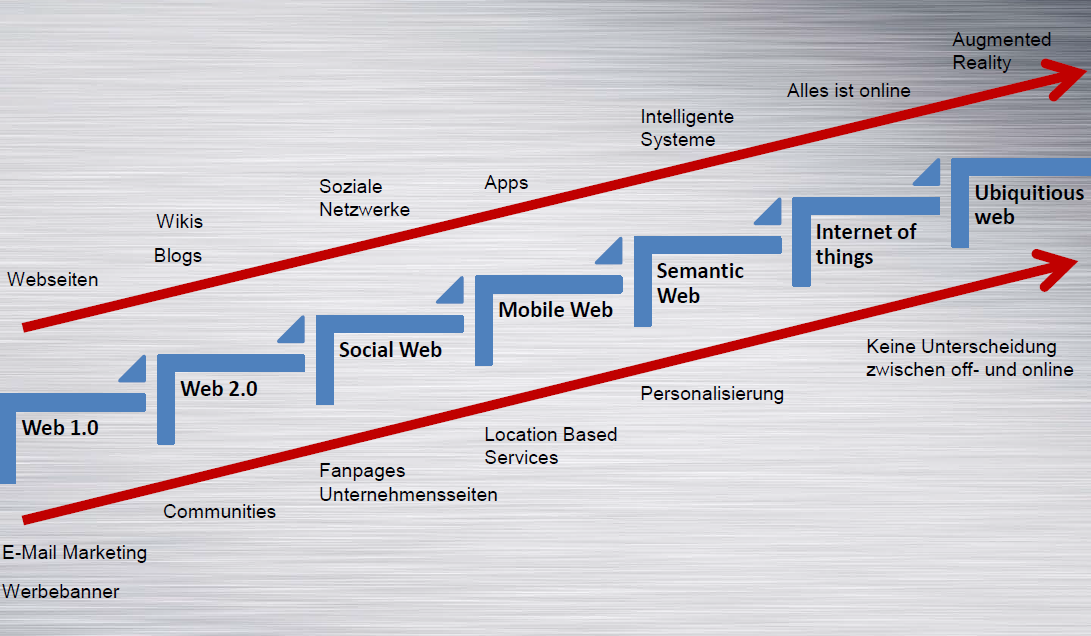
Wir befinden uns in einer sehr spannenden Zeit! Aktuell geht das Web gerade mit uns durch! Fast täglich entdeckt man neue Dienste, Trends und Technologien. Wenn man die Entwicklungsstufen des WWW betrachtet, so kann man erkennen, wo die Reise hingeht: In den Anfängen haben statische Inhalte das Web dominiert, mit dem Web 2.0 bekamen Nutzer die Möglichkeit selbst Inhalte zu generieren, Stichwort User Generated Content. Durch den Erfolg sozialer Netzwerke können Nutzer sich vernetzen um Inhalte zu teilen und zu diskutieren. Das Ganze ist nun Dank Smartphones und Tablets auch von unterwegs möglich. Der Trend geht nun dahin, dass sämtliche Geräte miteinander übers Web vernetzt sind und miteinander kommunizieren, seien es Autos mit integriertem Internet Zugang à la Connected Drive oder Kühlschränke die selbst Essensnachschub bestellen.
Doch hier tritt ein Problem des „alten“ Webs auf, das es zu lösen gilt: Webseiten werden in der Regel für Menschen entwickelt, nicht für Maschinen! Wie kann man das verstehen? Wenn man den HTML-Code einer typischen Website betrachtet, so enthält dieser ein bisschen Text, vielleicht ein paar Bilder und ein Video. Der Sinn dieser Inhalte erschließt sich für menschliche Betrachter sofort. Ein Menü wird als Menü erkannt, eine Adresse als Adresse, ein Name als Name und das Foto des Autors als Foto des Autors, usw. ;-)
Leider kann eine Maschine – z.B. eine Suchmaschine – relativ wenig mit diesen Informationen anfangen, das heißt die Bedeutung der Inhalte ist nur für Menschen verständlich.
<div id="menu"> <ul> <li>Menüpunkt</li> </ul> </div> <div id="content"> <h1>Kontakt</h1> Arrabiata Solutions GmbH Seidlstraße 25 80335 München <div id="footer">2013 Arrabiata</div> </div>
Glücklicherweise gibt es eine Menge an Bestrebungen um genau dieses Problem zu lösen. Ich möchte die Entwicklungen nun der Reihe nach vorstellen und erklären wie man sie nutzen kann.
- Semantik in HTML
- RDF & RDFa
- Microdata & Microformats
- Rich Snippets für Google und Co.
- Social Media-Semantik
- Nutzen und noch mehr Nutzen
Semantic Web
Die Idee des Semantic Web existiert schon seit den Anfängen des WWW. So hatte sein Erfinder Tim Berners-Lee bereits damals die Vision von Computern, die selbständig Informationen wie Termine austauschen. Das W3C hat sich dann auch mit einer eigenen Working Group dem Problem angenommen und das RDF (Resource Description Framework) entwickelt.
Das Semantic Web kann als Weiterentwicklung des World Wide Web betrachtet werden. Ziel ist, dass Maschinen die von Menschen zusammengetragenen Informationen verarbeiten und verstehen können sollen. Der Lösungsansatz ist bis heute der gleiche geblieben: Daten/Informationen werden mit eindeutiger Beschreibung ihrer Bedeutung (Semantik) versehen. Dies geschieht ganz einfach durch zusätzlichen Markup in der Webseite, oder wie im Fall von HTML5 durch neuen, aussagekräftigeren Markup.
Mit Hilfe dieser Auszeichnungen können bspw. mobile Geräte Telefonnummern direkt anrufen, Adressen im Routenplaner öffnen oder Termine gleich in den Kalender speichern. Aber auch Suchmaschinen können diese Infos nutzen, um die Suchergebnisse gleich entsprechend schöner darzustellen wie wir später im Fall von Googles Rich Snippets sehen werden. Und natürlich nicht zu vergessen: Die sozialen Netzwerke als heutzutage wichtigster Reichweitentreiber können Metainformationen verarbeiten.
Mehr Semantik in HTML5
![]()
Mit HTML5 wurde ein Haufen neuer Tags eingeführt, die einzelne Bestandteile einer Website klarer von einander abgrenzen. Hat man in den Anfängen des Webdesigns Layouts noch mit Tabellen aufgebaut, so wurden sie später hauptsächlich durch ineinander verschachtelte div-Container realisiert. Nur so ein <div>-Tag sagt halt nicht viel mehr aus als „hallo ich bin ein Container“. In HTML5 haben wir nun Tags für den Seitenkopf <header>, Menüs <nav>, Abschnitte <section>, Artikel <article>, die Randspalte <aside>, die Fußzeile <footer>, Abbildungen <figure> und viele mehr bekommen.
HTML5 Seitenaufbau
<header><nav> <ul> <li>Menüpunkt</li> </ul> </nav></header> <section> <article> <h1>Kontakt</h1> Arrabiata Solutions GmbH Seidlstraße 25 80335 München </article> </section> <footer>2013 Arrabiata </footer>
Neue Attribute in HTML5
Dazu kommen noch Attribute die Beziehungen der Tags erklären, wie bspw. das Relationship Attribut bei Links: Autor rel=“author“, Alternativ rel=“alternate“, Lesezeichen rel=“bookmark“, Hilfe rel=“help“, Lizenz rel=“license“, aber auch zur Seitennavigation rel=“next“ und rel=“prev“, oder zur Suche rel=“search“.Die Vorteile liegen auf der Hand:
- Echter Content kann besser von anderen Elementen abgegrenzt werden
- Positive Auswirkung auf die OnPage Optimierung
Es gibt aber auch Gefahren:
- Stuffing (überladener HTML-Code)
- Längere Ladezeiten weil viel mehr Code interpretiert werden muss
Deshalb sollte man seinen Code nicht zu sehr mit Semantik überladen.
RDF
Wie schon erwähnt steht RDF für „Resource Description Framework“, also einfach gesagt eine Methode bzw. ein Rahmen zur Beschreibung von Dingen. Das Tolle an RDF ist, dass man damit nicht nur Dinge beschreiben kann, sonder auch ihre Beziehung zueinander. Da RDF prinzipiell erst mal nur ein Konzept ist, kann es sehr unterschiedlich dargestellt werden, z.B. graphisch mit Pfeilen usw., aber natürlich auch mit Code, genauergesagt mit XML-Code. Das W3C hat für RDF eigens einen XML-Dialekt entwickelt.
Da RDF grundsätzlich etwas kompliziert ist, will ich an dieser Stelle nicht zu tief einsteigen und nur die Grundzüge erklären. Für das ordinäre Web ist nämlich der kleine Bruder RDFa meiner Meinung nach relevanter.
RDF funktioniert arbeitet mit Beziehungstripeln die immer aus Subjekt, Prädikat und Objekt bestehen, wie wir das aus der Grammatik kennen. Ein einfaches RDF-Tripel sieht z.B. so aus: „Thomas arbeitet für Arrabiata“. Die Ressource Thomas (Subjekt) hat also die Beziehung Arbeitsverhältnis (Prädikat) zu der Ressource Arrabiata (Objekt). Die einzelnen Ressourcen können dabei mit URIs (Uniform Ressource Identifier – die Mutter der URLs) eindeutig identifiziert werden, in der Web-Logik wäre das z.B. jeweils eine URL zum Profil der Person und zum Profil der Firma. Zu guterletzt lassen sich mit diesen Tripeln riesige Wissensdatenbanken mit unzähligen Beziehungen aufbauen. Diese nennt man dann Ontologien. Aber nun genug Semantic Web für den Anfang.
RDFa

RDFa steht für „RDF in Attributes“ und ist sozusagen die Vereinfachung von RDF für das Web. Das Prinzip ist denkbar simpel: In HTML kann man wunderbar Attribute nutzen um die einzelnen Ressourcen und deren Beziehungen zueinander zu beschreiben. RDFa ist deshalb auch die offizielle Empfehlung des W3C zur Einbettung von computerlesbaren Zusatzinformationen.
RDFa kann natürlich manuell in HTML-Code eingebettet werden, es gibt aber auch diverse Content Management Systeme wie Drupal oder WordPress, die RDFa schon standardmäßig unterstützen, oder es über Plugins verfügbar machen.
Einen kleinen Haken gibt es allerdings noch an der Sache: Es gibt nicht den einen Standard, sondern mehrere Vokabulare, die man für verschiedene Zwecke nutzen kann.
Die Standard-Vokabulare von RDFa sind:
RDFa in Action
Nun aber endlich mal ein kleines Bespiel wie RDFa-Code aussieht:
<div>Mein Name ist Thomas Kraehe, aber ihr könnt mich auch Tom nennen. Das ist meine Blog: <a href="https://www.digitale-wunderwelt.de" rel="v:url">www.digitale-wunderwelt.de</a>. Ich lebe in München und arbeite als Web Optimierer bei der Firma Arrabiata.</div>
Wie ihr seht, handelt es sich um ganz normalen HTML-Code, der um ein paar Attribute wie property=“v:name“ für den Namen oder property=“v:affiliation“ für die Firma erweitert wurde.
Mikrodaten / Microdata
So, um das Ganze etwas unübersichtlicher zu machen, gibt es nicht nur RDFa sondern auch noch Mikrodaten und Microformats :) Beide sind irgendwie ähnlich, aber auch doch wieder anders, getreu dem Motto „same same but different“!
Microdata ist eine WHATWG (Web Hypertext Application Technology Working Group) HTML Spezifikation die darauf abzielt HTML-Content mit Metadaten anzureichern – kennen wir irgendwie schon. Microdata nutzt allerdings <span>- und <div>-Tags als zusätzlichen Markup, die ebenfalls mit speziellen Attributen angereichert werden. Hier ein Beispiel:
<div>Mein Name ist Thomas Kraehe ihr könnt mich Tom nennen. Das ist meine Website: <a href="https://www.digitale-wunderwelt.de">www.digitale-wunderwelt.de</a> Ich lebe in München in Bayern und arbeite als Web Berater in der Agentur Arrabiata.</div>
Datum & Zeit
<time datetime="2013-06-24T9:00-18:00">24. Juni 2013, 9:00 Uhr</time>
Microformats
Und nun die Microformats – wie gesagt, alles irgendwie ähnlich. Aber keine Angst, bald kommt die Auflösung! Microformats sind kleine HTML-Muster zur Repräsentation häufig publizierter Objekte wie Menschen, Events, Blogbeiträgen, Reviews und Tags in Webseiten. Sie sind vermutlich der schnellste und einfachste Weg eine API zu den Daten und Informationen Ihrer Website bereitzustellen.
Microformats nutzen allerdings im Gegensatz zu RDFa und Microdata Klassen zur Identifikation von Entitäten (Dingen). Hier ein Beispiel:
<div class="vcard"><img class="photo" src="https://www.digitale-wunderwelt.de/wp-content/uploads/2009/05/thomas_2_crop_small_web.jpg"/> <strong class="fn">Thomas Kraehe</strong> <span class="title">Web Optimierer</span> bei <span class="org">Arrabiata</span> <span class="adr"> <span class="street-address">Seidlstraße 25</span> <span class="locality">München</span>, <span class="region">Bayern</span> <span class="postal-code">80335</span> </span></div>
Wie Ihr seht, sind die Zusatzinfos im Code sprich die Metadaten in den Namen der Klassen gebunden: Straße class=“street-address“, Postleitzahl class=“postal-code“, etc. Das schränkt einen natürlich irgendwie bei der Gestaltung ein, kann allerdings auch praktisch sein, weil man sich keine Gedanken darüber machen muss, wie man die Klassen benennt.
schema.org
Nun das große Finale! Happy happy :) Unter schema.org werden diese 3 Ansätze unter einen Hut gebracht. schema.org ist eine gemeinsame Initiative (man staunt…) der großen Suchmaschinen Bing, Google und Yahoo! Man hat hier versucht ein gemeinsames Set von Schemas (Vokabularen) für strukturierte Daten in Webseiten zu definieren. Dabei können alle 3 Methoden eingesetzt werden:
- RDFa
- Microformats
- Mikrodaten
Es bleibt euch überlassen, für welche Methode ihr euch entscheidet.
Google Rich Snippets
Was macht nun eine Suchmaschine genau mit diesen Informationen aus den Metadaten? Ganz einfach: Die Suchergebnisse lassen sich hübscher darstellen! Sie lassen sich z.B. durch hilfreichen Zusatzinformationen wie Bilder, Bewertungen oder Öffnungszeiten anreichern. Suchergebnisse werden dadurch informativer und emotional ansprechender. Sie vermitteln einen ersten Eindruck darüber welche Inhalte einen auf der Seite erwarten und nicht zuletzt steigern sie die Clickthrough-Rate (CTR) um etwa 20 – 30%. Außerdem verhelfen sie dem Seitenbetreiber zu qualifizierteren Besuchern, die sich wirklich für das Angebot der Website interessieren. Natürlich ist diese ganze Thematik besonders wichtig für alle Leute, die etwas über das Internet verkaufen wollen.
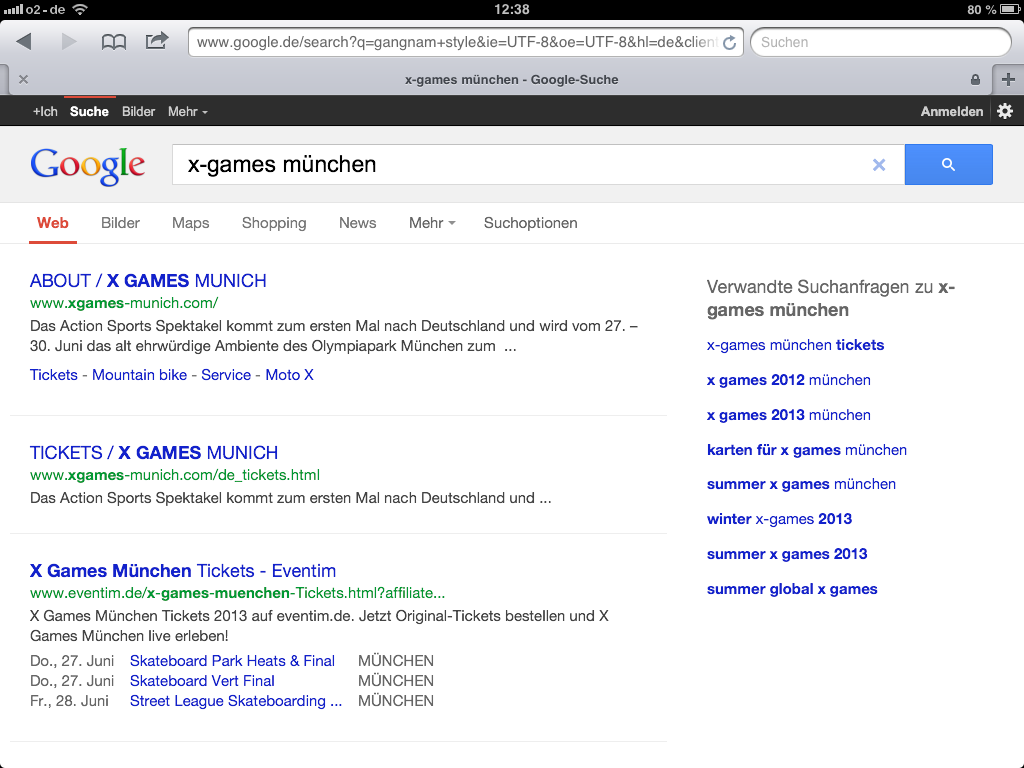
Google unterstützt aktuell Rich Snippets für die folgenden Inhaltstypen:
- Erfahrungsberichte
- Personen
- Produkte
- Unternehmen und Organisationen
- Rezepte
- Veranstaltungen
- Musik
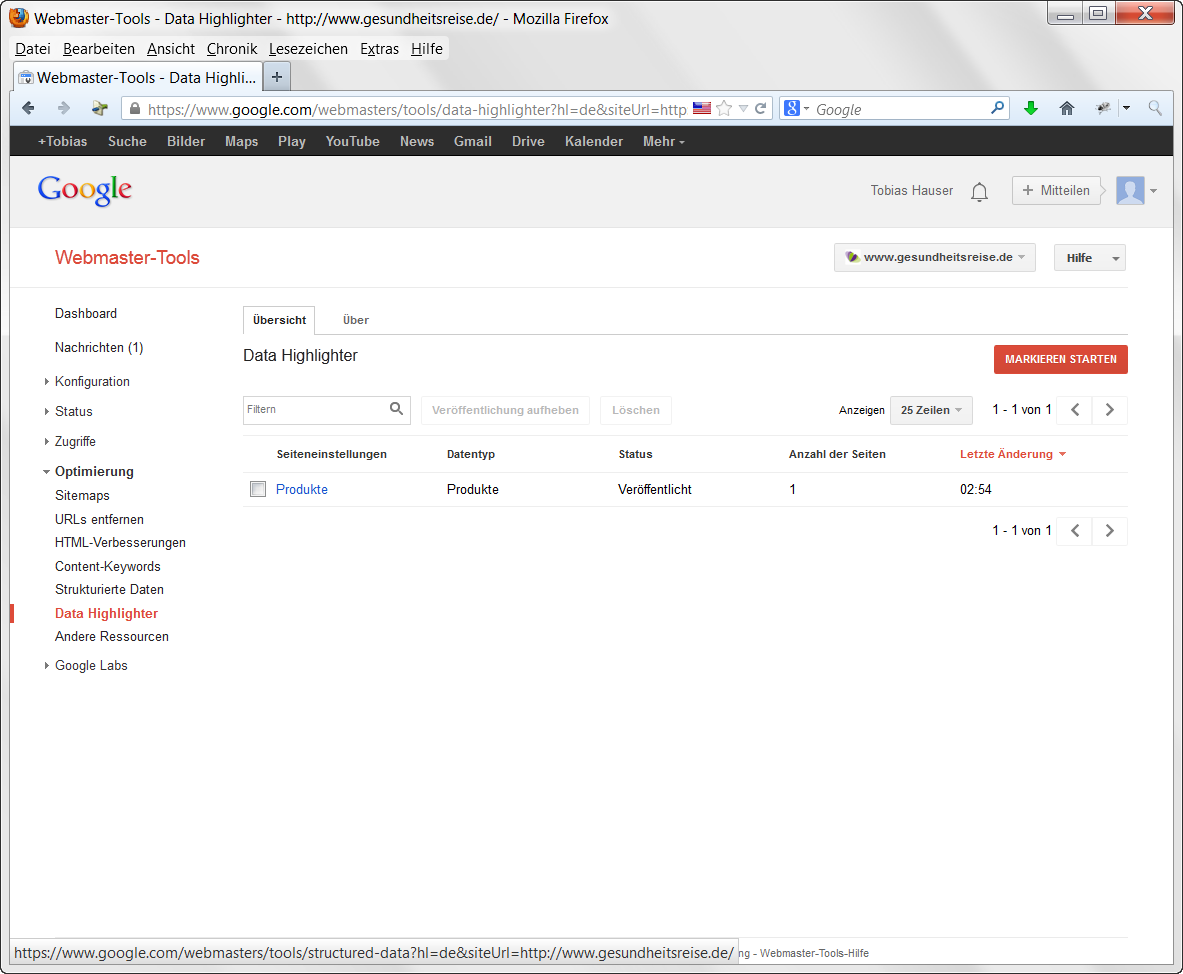
Der Data Highlighter
Wie kann ich feststellen wie meine Webseite in den Suchergebnissen dargestellt wird? Hierfür bietet Google in den Webmaster Tools den Data Highlighter an. Mit dem Data Highlighter kann man einerseits seine Seite scannen und die Darstellung von Metadaten überprüfen, man kann allerdings auch Muster strukturierter Daten auf der eigenen Website darstellen und Datenfelder mit der Maus markieren und taggen. Unterstützte Datentypen sind: Artikel, Veranstaltungen, Lokale Unternehmen, Restaurants, Produkte, Softwareprogramme und Filme.
Social Media und Semantik
Natürlich haben auch die sozialen Netzwerke schon längst das Potential von semantischem Markup erkannt und ihre eigenen Lösungen entwickelt.
Facebook Open Graph
Was bei Facebook unter dem Namen Open Graph läuft ist eigentlich auch nichts anderes als RDFa-Code, der in die eigene Website eingebettet wird. Der Hintergrund ist hier allerdigs, dass Facebook die Inforamtionen gezielt nutzen kann um sie im eigenen Netzwerk weiter zu verarbeiten. Mittels „Social Plugins“ können dritte Websites kleine Anwendungen bei minimalem Aufwand in das eigene Portal integrieren. Inhalte können so gezielt im sozialen Netzwerk geteilet werden. Einzelne Artikel oder ganze Seiten werden mittels Open Graph automatisch klassifiziert und semantisch ausgezeichnet. Die Einbettung erfolgt über Meta-Tags im HTML-Header.
Social Plugins machen jeden einzelnen Artikel oder eine Webseite zu einem Graph Objekt mit spezifischer ID (Ressource mit URI). Entwickler können relevante Informationen über die einzelnen Objekte über Facebook abrufen.
Hier ein Beispiel von Open Graph Code:
<meta property="og:url" content="http://www.nytimes.com/2015/02/19/arts/international/when-great-minds-dont-think-alike.html"/> <meta property="og:type" content="article"/> <meta property="og:title" content="When Great Minds Don’t Think Alike"/> <meta property="og:description" content="How much does culture influence creative thinking?"/> <meta property="og:image" content="http://static01.nyt.com/images/2015/02/19/arts/international/19iht-btnumbers19A/19iht-btnumbers19A-facebookJumbo-v2.jpg"/>
Twitter Cards
Und wieder heißt es „same same – but different“! Twitter hat mit seinen Twitter Cards quasi die Funktionalität von FB Open Graph nachgebaut. Mit Hilfe von Twitter Cards können nicht nur Medien an Tweets angehängt werden, die zum eigenen Content linken, sondern auch Metadaten in Websites integriert werden. Funktion und Syntax sind identisch wie bei Facebook und falls keine speziellen Twitter Tags in der Seite gefunden werden, greift Twitter auf die Facebook Tags zurück, quasi als Fallback-Lösung.
Pinterest – Rich Pins
Auch bei Pinterest gibt es eine änliche Funktionalität. Pinterest nennt seine semantischen Tags Rich Pins. Rich Pins bieten allerdings sogar Informationen in Echtzeit. Aktuell gibt es Rich Pins für Filme, Rezepte und Produkte.
Rich Pins können in verschiedenen Formaten eingebunden werden:
- oEmbed (Produkte)
- hRecipe, Microformate (Rezepte)
- Open Graph (Produkte)
- Microdaten (schema.org, alle)
Sie müssen allerdings von Pinterest validiert werden.
Hier ein Beispiel von Pinterest – oEmbed:
{
"provider_name": "Anbieter",
"url": "http://www.arrabiata.de/xyz",
"title": "Titel",
"description": "Beschreibung",
"product_id": "XY1",
"price": 22.00,
"currency_code": "EUR",
"availability": "in stock"
}
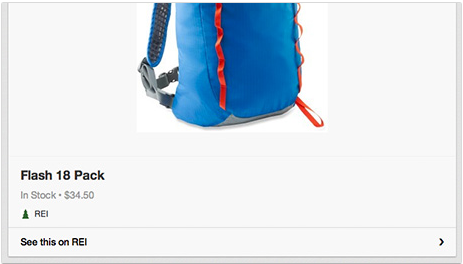
Im Screenshot ist zu sehen dass der Rucksack noch auf Lager ist. Der Preis wird auch in Echtzeit übermittelt.
Wie nutze ich den semantischen Code?
Wie kommen die Metadaten, Rich Snippets, Twitter Cards, etc. nun in meine Webiste?
In kleinen, manuell erstellten Websites können Sie den Code einfach händisch einfügen.
Semantische Auszeichnung im CMS
Wie sieht es bei einem Content Management System aus?
Es handelt sich hier eigentlich um eine reine Frontend-Angelegenheit. Aus MVC-Perspektive spielt sich alles in der View ab. Das heißt, die Integration lässt sich über die Themes/Templates steuern.
Für die meisten CMS gibt es bereits haufenweise Plugins! Oder wenn sie Glück haben, unterstützt ihr CMS semantischen Code von Haus aus, wie z.B. bei Drupal.
- Für WordPress gibt es bspw. das Plugin: Schema Creator
- Bei Drupal empfehle ich das Module: Schemaorg & Microdata
- Für Magento Shops gibt es das Modul: Msemantic
Achtung, es gibt auch Stolperfallen! SEO-Junkies werden vielleicht dazu verleitet hier und da zu tricksen! Davon kann ich nur abraten! Google ist schlauer! Entitäten müssen sichtbar sein!!! Versteckte Inhalte werden abgestraft. Mit Mikrodaten wird genau so viel Schindluder getrieben wie früher mit Meta-Keywords…
Verbreitung
Nur 13 % aller HTML-Seiten verwenden derzeit irgendeine Form strukturierter Auszeichnung.
49,3 % davon nutzen Microformate.
36,3 % nutzen RDFa und
14,4 % nutzen Microdata.
Fazit
Ich kann jedem Website-Betreiber den Einsatz von semantischen Code nur wärmstens empfehlen!
All in! Go for it! Just do it! It is easy!